
谷歌云的Speech-to-Text音转文加说话人识别接口使用示例
前提
确保拥有google账号并已配置好结算账号
准备好一个音频文件
一、配置ADC环境
首先进入谷歌云控制台,点击下图按钮激活Cloud Shell
初始化
Pick configuration to use:选1Select an account:选择你自己的邮箱编号,我这里选1Pick cloud project to use:选择你要应用到的项目id,我这里选2
创建本地身份验证凭据
gcloud auth application-default loginDo you want to continue (Y/n)?输入y此时会给你一个链接,点击链接跳转到确认页面,选择账号后并继续后,会跳到验证码页面,复制验证码并填入Cloud Shell中
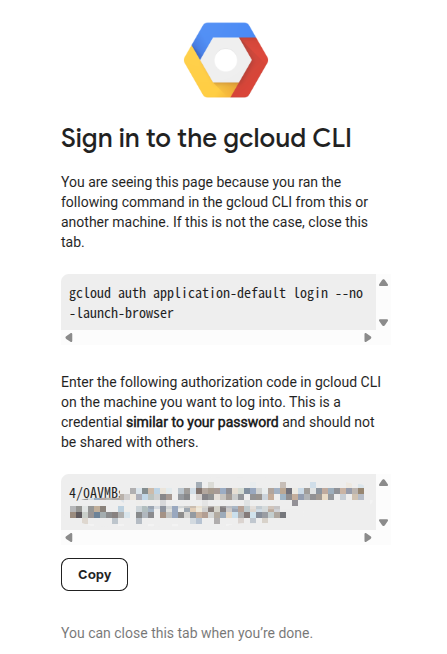
拿到上面打印出的证书的路径并打印内容
# 每一次的随机路径不一样 cat /tmp/tmp.A2jv5crnDz/application_default_credentials.json本地环境新建文件
~/.google-cloud-credentials.json,粘贴/tmp/tmp.A2jv5crnDz/application_default_credentials.json的内容
二、添加应用
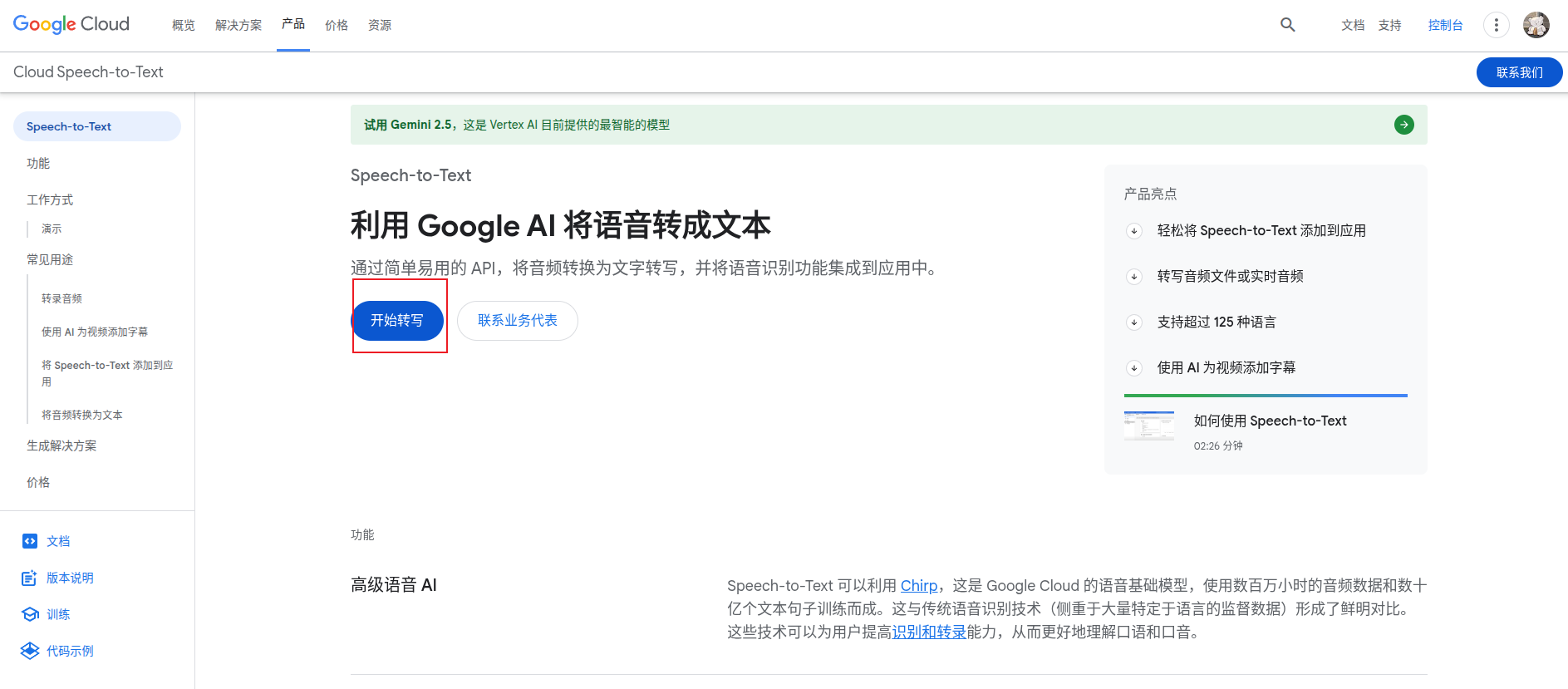
前往上述链接添加应用,我这里已经添加好了
三、Demo
添加依赖
uv add google-cloud-speech示例代码(main.py)
from google.cloud import speech_v1p1beta1 as speech
from google.auth import default
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "/home/<username>/.google-cloud-credentials.json"
os.environ["GOOGLE_CLOUD_PROJECT"] = '<你的项目id-2>'
credentials, _ = default()
client = speech.SpeechClient()
speech_file = some-audio.wav"
with open(speech_file, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
diarization_config = speech.SpeakerDiarizationConfig(
enable_speaker_diarization=True,
min_speaker_count=1,
max_speaker_count=10,
)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="zh-CN",
diarization_config=diarization_config,
)
print("Waiting for operation to complete...")
response = client.recognize(config=config, audio=audio)
# The transcript within each result is separate and sequential per result.
# However, the words list within an alternative includes all the words
# from all the results thus far. Thus, to get all the words with speaker
# tags, you only have to take the words list from the last result:
result = response.results[-1]
words_info = result.alternatives[0].words
# Printing out the output:
for word_info in words_info:
print(f"word: '{word_info.word}', speaker_tag: {word_info.speaker_tag}")
print(result)
运行
uv run main.py结果
Waiting for operation to complete...
word: '但', speaker_tag: 1
word: '是', speaker_tag: 1
word: '在', speaker_tag: 1
word: '一', speaker_tag: 1
word: '米', speaker_tag: 1
word: '左', speaker_tag: 1
word: '右', speaker_tag: 1
word: '的', speaker_tag: 1
word: '距', speaker_tag: 1
word: '离', speaker_tag: 1
...这里有个问题,如果转录的文件是中文,那么所识别的说话人始终是1个,英文文件不会存在这个问题
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Ryan的折腾日记
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果
